
Lately I've been doing some thourough research about database optimization techniques and how some simple tuning techniques and SQL best practices can take you a long way in achieving an optimized, efficient, clean and mantainable database system. A database is usually the very bottom layer of any website, thus inefficiencies and extra overheads can result in a bottle neck situation within your data layer which will naturally have a major impact on the wholistic performance of your online system. Around 4 weeks ago I explained how you can improve you TSQL and SQL statements just by following a few best practices, if you need a quick refreshment here's a link to the previous SQL optimization blog. I hope some of you actually found those tips useful, because today we're going to build up on those tips and go further in optimizing our database using more elaborate techniques such as indexing, analyzing Query execution plans, Views and Indexed views.
Indexing
We've all heard about indexes and how they can be used to optimize data retrieval queries. The problem is that people are often confused where to put indexes and which columns are suitable candidates for indexing. Firstly lets make sure we fully understand what an index is and how it can be useful only if used in the right places. Lets start off by saying that there are two main types of indexes:
- Clustered Indexes
- Non Clustered Indexes
The first time I really got the gist of what indexes are was after I read a really good example about a common book library. If all the books are unsorted and placed randomly on shelves, the library would spend quite some time looking all over the place for a requested book. However if all the books were sorted and given an ID or a number and people were aware of this number, they could just go to the librarian and ask for the book with that specific number. Given that the books are sorted sequentially according to their number, the librarian should find the requested book quite easily won't you say? This is a Clustered Index and its usually in the form of a Primary key. That is why in the previous blog I've mentioned the importance of having 1 primary key in each table which can uniquely identify 1 row in the table.
Now what if someone came in and asked for a book but could only remember the name of the book, what would the librarian do? One way to do it is to have a catalogue of all the books in alphabetical order and their corresponding ID. This way the librarian can look for the book in the catalogue first, find the book by the book title in ascending order and then look for the corresponding ID. This is what a Non Clustered Index is in concept. It keeps track of other coulmns which will be frequently used in searches in the form of B Trees and have their values pointing to the Clustered Index of the actual data.
After understanding what a Clustered and a Non Clustered Index is, we can now start to think about some good candidate coulmns which would make good Clustered Indexes. Just to help you out in choosing good clustered Index coulmns, ask yourself the following questions:
- Is the column being used frequently during searching?
- Is the column being used to join tables togather?
- Is the column a foreign field?
- Does the coulmn have a high selectivity index (it can retrieve from 0-5% of the rows in the database for a particular value)?
- Is it used in an Order By?
If the coulumn falls under any of the above criteria, than it should be considered as a clustered index.
An index can be simply created using native SQL as follows:
CREATE INDEX NCLIX_OrderDetails_ProductID ON dbo.OrderDetails(ProductID)
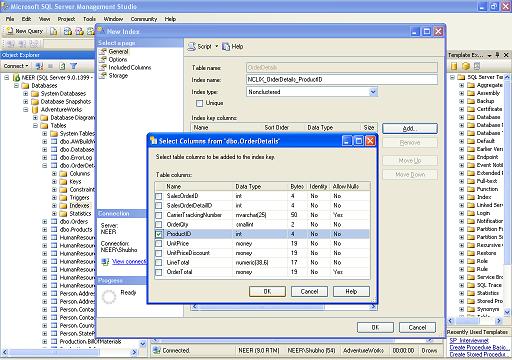
Alternatively one may also use SQL Server Management Studio and create Indexes using a more user friendly GUI.
Views
Sometimes we have some particular queries which are being used over and over again by multiple stored procedures which retrieve a substantial amound of data. This is where Views come to the rescue. Views are basically pre compiled queries residing as objects in the database. Views can then be further used to perform heavy join operations. Views on their own will not improve your performance significantly, however if we apply indexing on the Views themselves we are defenitley in for a treat. When we created Indexes on Views, the results of the views are temporarliy stored and no execution of the query is required to get the results of the view. This is called an Indexed View. In an indexed view, the database engine processes the SQL and stored the result in the data file just like having a clustered table, thus having indexed views will significantly boost your query performance. However this does actually come at a price like everything else. When base tables being used by the View are changed, the database engine, needs to update its indexes and so it would need to execute the View in order to store the new results.
Creating an Index view is not overly complicated, you just need to make sure you only do it where necessary so as to make the best use of the precompiled result set. To create an Indexed view:
CREATE VIEW dbo.vOrderDetails WITH SCHEMABINDING AS SELECT...
- Create the View specifying the SCHEMABINDING option
- Create a unique clustured index on the View
- Create a non-clustered index on the View
NB. You cannot change the schema of the underlying tables used within the View when you specify the SCHEMABINDING option.
Query Execution Plans
When executing queries, the database engine will carry out a sophisticated analysis on your data and the query processing involved in your queries to determine the best query execution plans. The query execution plans of the database base engine are determined by several factors such as:
- Statistics
- Volume of data
- Index variation
- Parameter value in TSQL
- Load on server
By analysing the execution plan we can determine whether our indexes are really optimizing the data retrieval processes and whetrher we should change or apply more indexing to our queries. Lets take a look at a query on a table with no indexing at all:
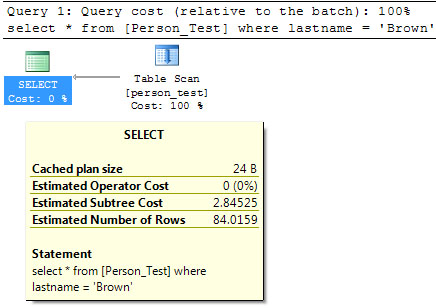
What matters to us the most is the Costs. The estimated Subtree Cost can help us determine how expensive it is for the query optimizer to execute this query an all other operations within the same subtree. The lower the value, the better.
let us now create a non clustered index on the 'LastName' column. As explained earlier this will help the database engine make a search first on the Non clustered Index and then search for the real ID of the item as shown in thequery execution plan below:
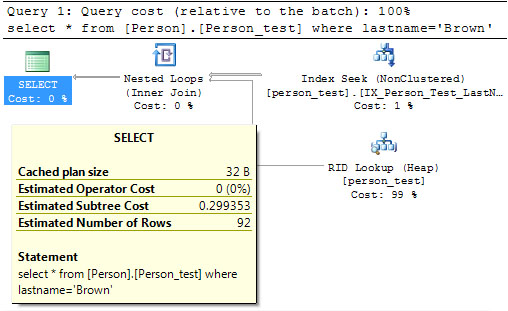
As you can see, the query optimizer first uses the Non Clustered index to find the last name and then uses that result to find the actual location of the resource within the Heap. As you can see the Estimated Subtree Cost has drastically decreased.
To check the data execution plan all you have to do is to 'Include execution Plan' button on your MSSQL Server Management Studio and after executing the query, the Execution Plan will be included as part of your results. From the 'Query' menu, you can just click on the 'Include Execution Plan':

There are much more tools and Optimizations which we can discuss, such as the SQL Profiler but for today it was very important to understand how the SQL Server engine works and how we can optimize it using simple indexes. In future blogs I will go into detail and explain two important tools:
- Database Tuning Advisor
- SQL Server Profiler
For the next couple of weeks we will not be talking about optimizations and tips and tricks to help you improve you websites and online systems. We will however, be talking about the Dublin Web Summit 2013 which we will be attending to promote one of our newest cutting edge technology website. I can't really spoil the surprise in this blog however I can promise you that you'll hear about it in the next two weeks.
Untill then, thanks for reading.