Back in 2012 I had posted a blog explaining the benefits of Multi-Tier Architectures and how seperating the layers can help us build a more robust, mantainable solution. We had split the architecture into 3 layers and explained how each is wired to the other whilst still mantained independently. Today we will take the Multi-Tier architecture a step further and introduce the Onion architecture, a term which was initally coined by Jeffrey Palermo (although the concept has been around earlier). We will first take a look at the traditional N-Tier architecture and then we will identify the various flaws in this architecture if you're building a large sophisticated system which will keep on evolving throughout the years.
The Multi-Tier architecture
The multi-tier architecture was a breath of fresh air when compared to previous architectures where were no layers were present to seperate the various concerns within a system. It solved various problems related to mantainability, scalability and flexibility however there was still a considerable number of dependencies amongst the layers themselves as shown in the diagram below:
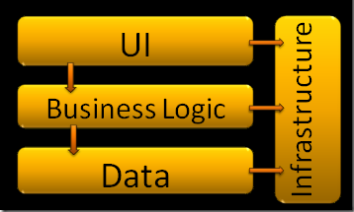
Using the Inversion of Control principle we were able to decouple the layers and inject the dependencies whenever and however we wanted. However the UI was still very much dependent on the implementation of the Business Layer which was in turn highly dependent on the implementation of the Data Layer. Each subsequent layer is dependent on the layers beneath it with an infrastructure layer supplying helpers to all the other layers. Without any coupling the system will not work however this layered architecture does create some unnecessary coupling which can be improved using the Onion archiecture.
The Onion architecture
The Onion architecture relies heavily on the inversion of control principle which I had discussed a couple of months back. In the same blog I mentioned how the 'Separation of Concerns' concept and the importance of not having tight coupling amongst layers which do not neccesarily need to be dependant on eachother. I had also explained how using the 'Inversion of Control' principle with the help of contracts, each of the layers know what to 'expect' from eachother without actually knowing how the information will be processed. If you have read both blogs about Multi-Tier architectures and Inversion of Control then you are half way there to understand and design your solution using the Onion architecture.
In simple terms, the Onion architecture comprises of Multiple centric layers interfacing eachother towards the core representing the domain of the problem. The diagram belows shows sample layers of the Onion architecture:
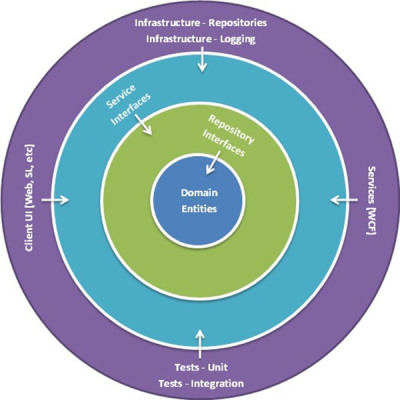
The whole architecture does not depend on the Data layer as in classic Multi-Tier architectures but on the actual domain models. The domain models represent the entities or subjects of the problem and are at the very heart of the architecture. The data storage layer (whether its a database or a file system) is external to the Onion architecture and can be easily replaced without impacting the rest of the solution.
Domain Entities
As explained in the diagram the 'Domain Entities' are at the heart of the architecture, the reason being is that the whole solution aims at solving a problem involving these domain entities and so they are the least probable to be replaced in the future. Domain entities in a School project could include:
- Students
- Teachers
- Books
- Classes
- Subjects
Repository Interfaces
The next layer is the repository interfaces. In previous blogs I had explained the benefits of using a Repository Layer to separate the dependency on the acutal database infrastructure used. The onion architecture takes this one step further and dictates that only the repository interfaces should be closest to the Domain Models. The repository layer should expose contracts using the Domain models such as:
- Save Student
- Get Teacher
- Get All Subjects
It should only return Domain Models without actually exposing the implementation of how this is done. The actual implementation of the repository layer is external to the Onion architecture and can be done usingh several techniques such as ORMs (Entity Framework, NHibernate), NoSql databses (MongoDb), Document databases (Raven Db). Using this architecture the rest of the layers are not concerned where the domain related data is coming from as long as they know that the repository interfaces can provide it. We can then implement the repository interfaces in various ways and we can even switch amongst implementations at run time using dependency injection and inversion of control.
Application Interfaces
The next layer is the application interfaces. Whereas the Repository Interfaces are more domain oriented, the Application Interfaces are more application oriented, in the sense that they should provide services to satisfy the needs and requirements at an application level. Same as the Repository interfaces layer, this layer does not provide any concrete Application Service implementation. It constitues in a number of contracts which are meant to serve the application at a more presentation level. The actual implementations can vary and should also be external to the architecture. Same as the Repository Interfaces, the implementation of the Application Interfaces could be Web Services (WCF or Web API) or actual concrete classes. This does not concern the coupling of the solution as the only coupling within the solution is between contracts and interfaces towards the domain model.
Other components
Any solution needs extra modules which provide infrastructure helpers and tools. These modules should be attached externally to the Onion architecture and should not be dependant on anything else. I also find it very helpful to include a bootstrapper module which handles all the wiring and dependencies amongst the interfaces and their respective implementations. This bootstrapper module is usually called in the 'Application Start' event and depending on certain configurations, implements all the interfaces using the appropriate concrete implementations.
That's all, I hope that you get a better picture of what the Onion architecture is and how its should be used. I feel that I must stress out that this architecture is only suitable for large robust projects which will be mantained for a long time. If you're building a small website, you should stick to the traditional Multi-Layered architecture and not bother with the complexities of having such a sophisticated architecture. However, for the larger systems I hope that from this blog you can understand the flexibility and mantainability such an architecture can provide to your solutions.
Thanks for reading,
Shaun